Does this work with any text on page (vs just inputs)?
Currently dealing with several digital textbooks - that I fucking purchased - from Elsevier that disable copy functions, which makes pulling chunks of text from a page to take notes a pain in the ass. I’ve resorted to just using the snipit tool to capture tiny screenshots of the text I want, but that’s ofc significantly less ideal than just highlighting text and hitting Ctrl+C.
It’s a really good extension. Has a tendency to break some functionality of websites when it’s on, but it’s easy to just toggle it on, refresh the page, grab what you need, then toggle it off again.
That sounds right up my alley because another pet peeve of mine is when they block me from opening an image in a new tab via the right click menu. My eyes aren’t what they used to be and I need to ZOOM sometimes.
ShareX has an OCR feature. It’s a tool for taking screenshots and recordings, with support for configurable workflows which can do all sorts, including extract text from the snipped area and copy it to the clipboard.
Okay that actually sounds pretty amazing… but I can’t get it to work. Win+shift+T seems to just cycle through the icons pinned in my taskbar. I’ll do some googling to see if I can figure out why that is, but if you know a quick fix, then yes please!!
I just thought of a possible bypass. Maybe a phone’s “scan document” function can help with that? Provided that the text is clear, you may be able to scan a webpage and save it as a scanned document. Then open the doc on your phone (or other device), and you should be able to highlight and copy the scanned text.
Okay, maybe not. I tested it with this very page and although the copied text got the gist, I still would’ve had to go back and edit things. But eh, YMMV. It could be a valid work-around for somebody, just with different text or using a different device.
Usually I just leave them as little image blocks of text cuz ain’t nobody got time for dat. When I actually do want to fully convert it (usually only bother if I’m sending something out to the class), then I’ll save the whole doc as a PDF and then run it through an optical character recognition service like this one. There are ways, they just suck when a feature like copy exists.

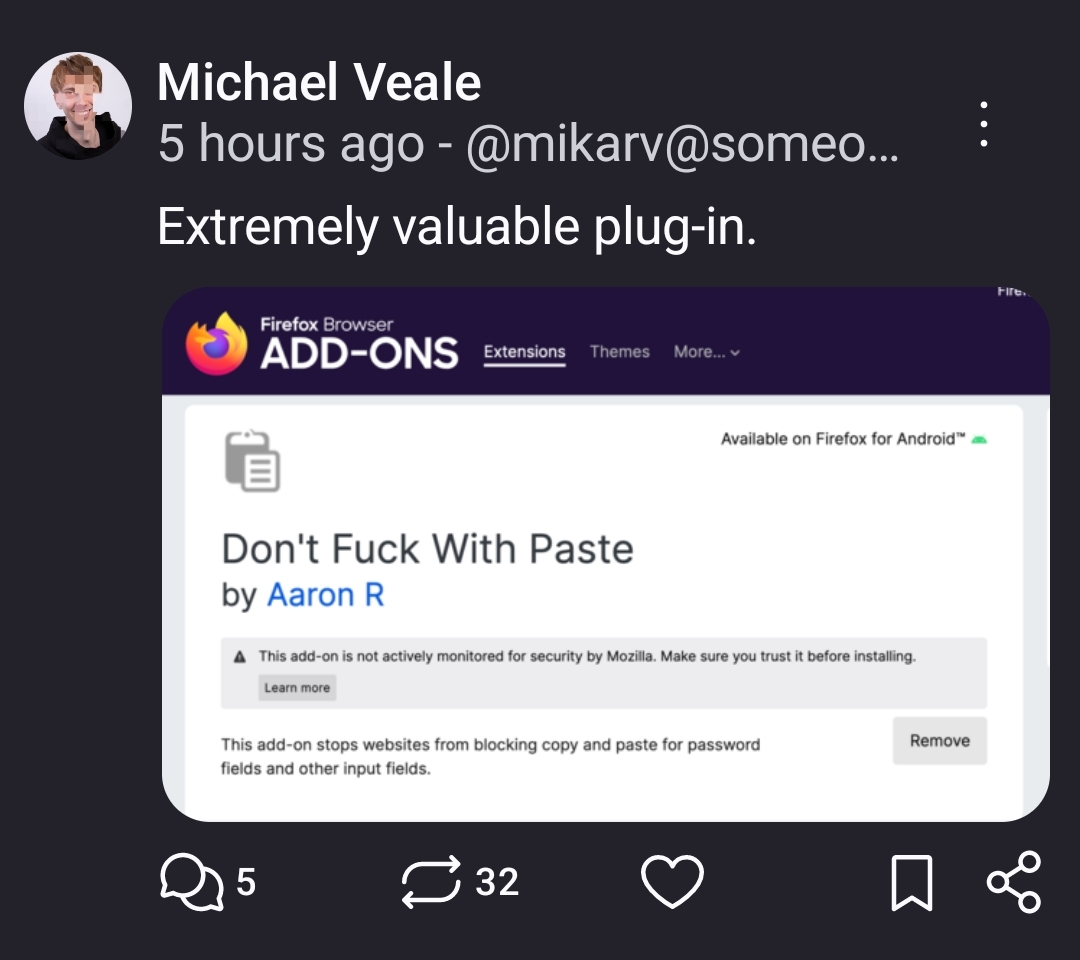{kind=link}
Does this work with any text on page (vs just inputs)?
Currently dealing with several digital textbooks - that I fucking purchased - from Elsevier that disable copy functions, which makes pulling chunks of text from a page to take notes a pain in the ass. I’ve resorted to just using the snipit tool to capture tiny screenshots of the text I want, but that’s ofc significantly less ideal than just highlighting text and hitting Ctrl+C.
I find that pressing Ctrl+C while highlighting the text (still holding left click) works, at least with Cengage
There is a Firefox extension called Absolute Enable Right Click & Copy that works great for a lot sites that block you from being able to copy.
Link for the lazy: https://addons.mozilla.org/en-US/firefox/addon/absolute-enable-right-click/
It’s a really good extension. Has a tendency to break some functionality of websites when it’s on, but it’s easy to just toggle it on, refresh the page, grab what you need, then toggle it off again.
That sounds right up my alley because another pet peeve of mine is when they block me from opening an image in a new tab via the right click menu. My eyes aren’t what they used to be and I need to ZOOM sometimes.
ShareX has an OCR feature. It’s a tool for taking screenshots and recordings, with support for configurable workflows which can do all sorts, including extract text from the snipped area and copy it to the clipboard.
If you’re using Windows, there is a utility included in PowerToys that you might find useful to get the text from those screenshots: https://learn.microsoft.com/en-us/windows/powertoys/text-extractor
Okay that actually sounds pretty amazing… but I can’t get it to work. Win+shift+T seems to just cycle through the icons pinned in my taskbar. I’ll do some googling to see if I can figure out why that is, but if you know a quick fix, then yes please!!
I just thought of a possible bypass. Maybe a phone’s “scan document” function can help with that? Provided that the text is clear, you may be able to scan a webpage and save it as a scanned document. Then open the doc on your phone (or other device), and you should be able to highlight and copy the scanned text.
Okay, maybe not. I tested it with this very page and although the copied text got the gist, I still would’ve had to go back and edit things. But eh, YMMV. It could be a valid work-around for somebody, just with different text or using a different device.
Usually I just leave them as little image blocks of text cuz ain’t nobody got time for dat. When I actually do want to fully convert it (usually only bother if I’m sending something out to the class), then I’ll save the whole doc as a PDF and then run it through an optical character recognition service like this one. There are ways, they just suck when a feature like copy exists.
Screenshot, paste to GPT and ask it to parse to text.