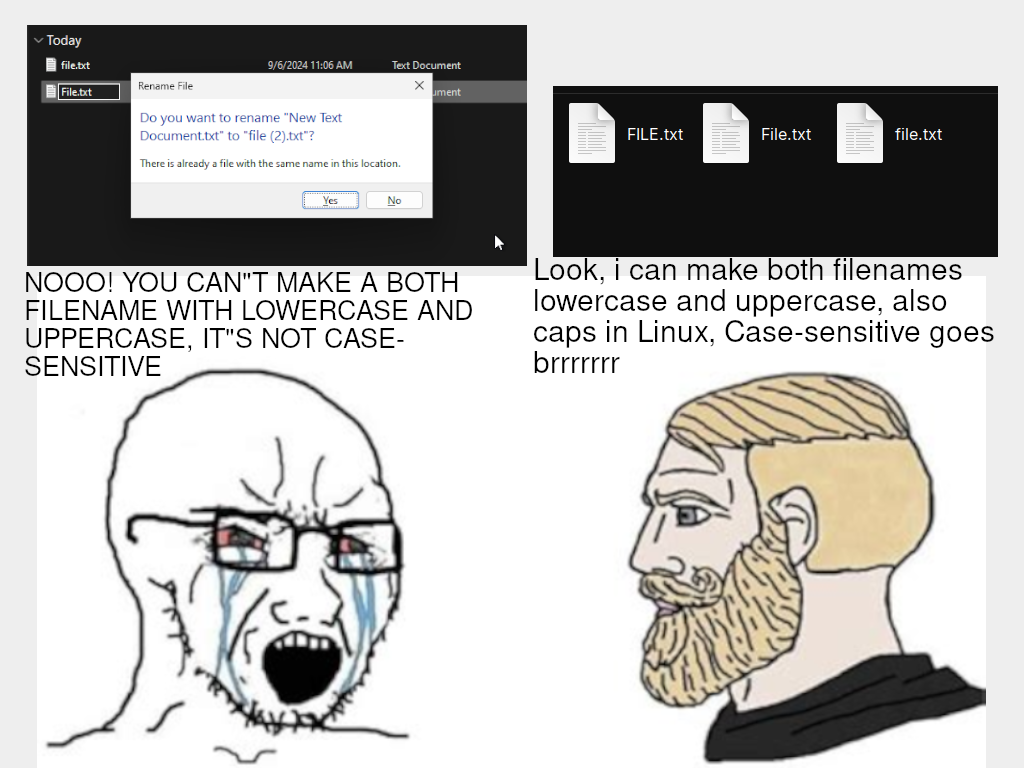
I don’t think there’s a need for File.txt and fILE.txt
It’s not so much about that need. It’s about it being programmatically correct. f and F are not the same ASCII or UTF-8 character, so why would a file system treat them the same?
Having a direct char type to filename mapping, without unnecessary hocus pocus in between, is the simple and elegant solution.
That’s some suckless level cope. What’s correct is the way that creates the least friction for the end users. Who really cares about some programming purity aspect?
Thanks, really constructive way of arguing your point…
Who really cares about some programming purity aspect?
People who create operating systems and file systems, or programs that interface with those should, because behind every computing aspect is still a physical reality of how that data is structured and stored.
What’s correct is the way that creates the least friction for the end users
Treating different characters as different characters is objectively the most correct and predictable way. Case has meaning, both in natural language as well as in almost anything computer related, so users should be allowed to express case canonically in filenames as well. If you were never exposed to a case insensitive filesystem first, you would find case sensitive the most natural way. Give end users some credit, it’s really not rocket science to understand that f and F are not the same, most people handle this “mindblowing” concept just fine.
Also the reason Microsoft made NTFS case insensitive by default was not because of “user friction” but because of backwards compatibility with MSDOS FAT16 all upper case 8.3 file names. However, when they created a new file system for the cloud, Azure Blob Storage, guess what: they made it case sensitive.


{kind=link}
It’s not so much about that need. It’s about it being programmatically correct.
fandFare not the same ASCII or UTF-8 character, so why would a file system treat them the same?Having a direct
chartype to filename mapping, without unnecessary hocus pocus in between, is the simple and elegant solution.That’s some suckless level cope. What’s correct is the way that creates the least friction for the end users. Who really cares about some programming purity aspect?
Thanks, really constructive way of arguing your point…
People who create operating systems and file systems, or programs that interface with those should, because behind every computing aspect is still a physical reality of how that data is structured and stored.
Treating different characters as different characters is objectively the most correct and predictable way. Case has meaning, both in natural language as well as in almost anything computer related, so users should be allowed to express case canonically in filenames as well. If you were never exposed to a case insensitive filesystem first, you would find case sensitive the most natural way. Give end users some credit, it’s really not rocket science to understand that
fandFare not the same, most people handle this “mindblowing” concept just fine.Also the reason Microsoft made NTFS case insensitive by default was not because of “user friction” but because of backwards compatibility with MSDOS FAT16 all upper case 8.3 file names. However, when they created a new file system for the cloud, Azure Blob Storage, guess what: they made it case sensitive.